Quando lavori con database come MySQL, ottimizzare la velocità delle tue query è fondamentale. Uno degli strumenti principali per farlo sono gli indici. In questo articolo vedremo cos’è un indice, come funziona, quali tipi esistono e come usarli correttamente nei tuoi database.
Cos’è un indice in un database MySQL
Immagina di avere una grande biblioteca dove i libri non sono ordinati: per trovare un libro specifico potresti dover controllare tutti gli scaffali uno per uno. Questo è simile a una tabella MySQL senza indice: per trovare un valore specifico, MySQL deve potenzialmente leggere tutte le righe.
Un indice è come la mappa o l’indice dei contenuti di un libro — ti permette di saltare direttamente alla parte giusta senza leggere tutto.
Pensa a una tabella MySQL come a una cartella di documenti. Senza indice, per trovare un documento devi aprire tutte le cartelle una per una. Con l’indice hai una lista di contenuti che ti dice subito dove si trova ogni documento.
In termini tecnici, MySQL utilizza strutture dati avanzate (come B-tree o hash) per rendere i riferimenti veloci ed efficienti.
Perché servono gli indici?
Per comprendere davvero l’importanza degli indici, partiamo da un esempio concreto. Consideriamo la query SQL:
select * from cities where city_id = 33
Questa query cerca una voce nella tabella delle città dove city_id è 33. Ora immaginiamo che MySQL memorizzi i dati di questa tabella in una cartella sul disco chiamata city . All’interno di questa cartella ci sono i file city_1.txt, city_2.txt … city_10.txt e altri, dove ogni file contiene informazioni su una città.
Se nella tabella abbiamo un numero limitato di città, eseguiremo la ricerca abbastanza rapidamente. Ma prendiamo la situazione in cui abbiamo migliaia di città. Per trovare il record di cui ha bisogno, MySQL deve controllare tutti i file in quella cartella finché non trova city_10.txt . Questo può accadere molto lentamente.
Gli indici vengono in soccorso. L’indice per il campo city_id può essere pensato come un array associativo (o oggetto JSON), dove la chiave è city_id e il valore è il nome del file che memorizza questa città. Quindi, utilizzando un indice, MySQL può accedere immediatamente al file desiderato, bypassando tutti gli altri.
Gli indici sono come il sommario di un libro. Nella vita reale, utilizziamo il sommario per trovare rapidamente in quale pagina si trova la sezione di cui abbiamo bisogno. Allo stesso modo, MySQL utilizza gli indici (nel nostro esempio) per trovare rapidamente il percorso del file in cui sono archiviati i dati.
Un indice in un database è una struttura dati speciale progettata per migliorare la velocità di ricerca e recupero di record da una tabella in base ai valori di uno o più campi. Può essere implementato utilizzando diversi algoritmi e strutture dati, come alberi o tabelle hash, a seconda delle specifiche del sistema di gestione del database.
Sebbene questo esempio aiuti a comprendere il concetto, è opportuno ricordare che l’implementazione reale degli indici in MySQL è molto più complessa ed efficiente di questa mappatura semplificata. Considereremo l’analisi dettagliata dell’implementazione degli indici in MySQL nella prossima sezione.
Tipi di indici
Esistono quattro tipi di indici in MySQL:
- Il B-tree è uno dei tipi di indici più popolari necessari per le ricerche di intervalli o corrispondenze.
- R-tree: richiesto per la ricerca in base alle coordinate.
- Hash: non supporta le ricerche per intervallo. Questo indice può essere utilizzato nelle tabelle dei tipi di memoria. La particolarità di questa tipologia è che i dati non vengono memorizzati sul disco, ma nella RAM.
- FullText: questo tipo di indice risolve i problemi della ricerca full-text. In poche parole, si tratta di una ricerca per frasi, parole, occorrenze di parte di una parola, ecc.
Nel resto dell’articolo ci concentreremo sugli indici B-tree, i più utilizzati in MySQL.
Una delle caratteristiche principali degli indici B-tree è che sono archiviati in file separati su disco. Questi file contengono già immediatamente una struttura dati sotto forma di albero binario. Cioè, il DBMS può ottenere rapidamente i dati necessari senza la necessità di una scansione completa della tabella. Questo approccio all’archiviazione degli indici accelera notevolmente le operazioni di ricerca e recupero.
Questa struttura dati è organizzata in modo tale che per trovare il record desiderato venga utilizzata una ricerca binaria, grazie alla quale la ricerca negli indici B-tree è molto veloce.
La caratteristica principale è la struttura. Ogni nodo dell’albero ha:
- Chiave. Questo è il valore da cercare.
- Puntatori ai sottonodi. Aiutano a spostarsi in altre parti dell’albero.
- Collegamento ai dati. L’indirizzo del file e la riga in cui sono archiviate le informazioni.
Diamo un’occhiata alla visualizzazione dell’albero binario per l’indice nella colonna city_id con 20 città:
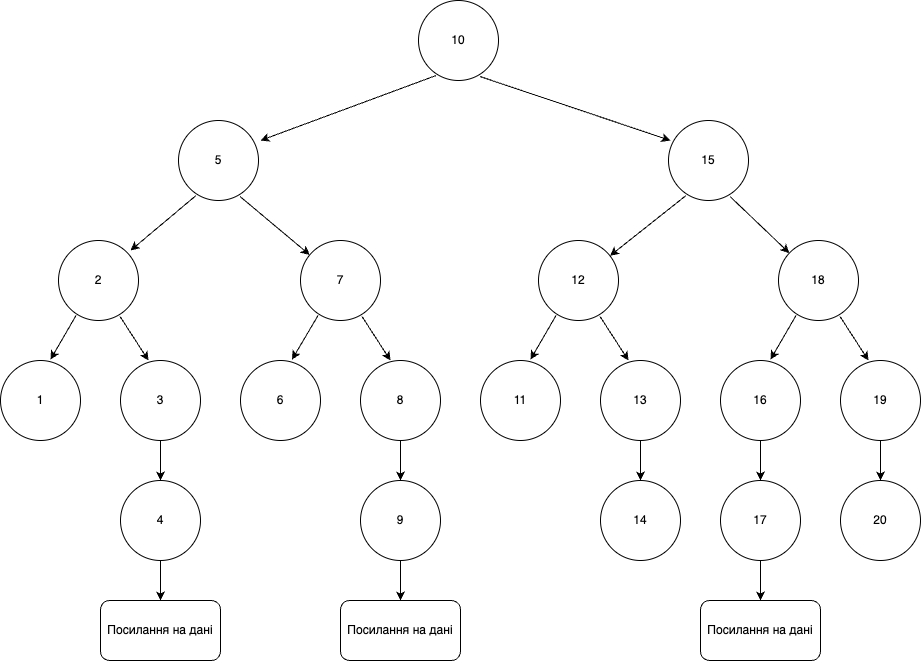
Ad esempio, dobbiamo trovare una città che abbia city_id=17 . Questi cerchi con numeri sono chiamati nodi. Iniziamo dal nodo principale e procediamo lungo l’albero, eseguendo operazioni di confronto:
- 17 >= 10? Sì, quindi andiamo al nodo giusto.
- 17 >= 15? Sì, quindi andiamo al nodo giusto da 15.
- 17 >= 18? No, quindi andiamo al nodo sinistro da 18.
- 17 >= 16? Sì, quindi andiamo al livello inferiore.
- Qui vediamo un nodo con city_id=17 .
Come puoi vedere, questo algoritmo ha trovato la città giusta in cinque operazioni di confronto.
Classificazione degli indici
Gli indici si dividono in due categorie:
- Clusterizzati
- Non clusterizzati
In InnoDB ogni tabella ha sempre un indice cluster:
- se esiste una chiave primaria, viene usata quella
- altrimenti il primo indice univoco
- se nessuno dei due esiste, MySQL crea un ID interno nascosto
La differenza principale è che:
- l’indice cluster punta direttamente ai dati sul disco
- l’indice non cluster punta all’indice cluster
Considera un esempio basato sulla tabella delle città , dove city_id è la chiave primaria. Ma nessuna città può esistere senza un paese, quindi aggiungiamo alla tabella la colonna country_id con l’indice corrispondente:
CREATE TABLE cities ( city_id INT AUTO_INCREMENT, country_id INT, name VARCHAR(255) NOT NULL, latitude DECIMAL(9,6), longitude DECIMAL(9,6), PRIMARY KEY (city_id), INDEX (country_id) );
Nella tabella delle città, city_id funge da indice cluster e l’indice su country_id è non cluster. Dopotutto, l’indice non cluster country_id punta a city_id, che indica esattamente dove sono archiviati i dati corrispondenti sul disco. Questo può essere rappresentato come segue:
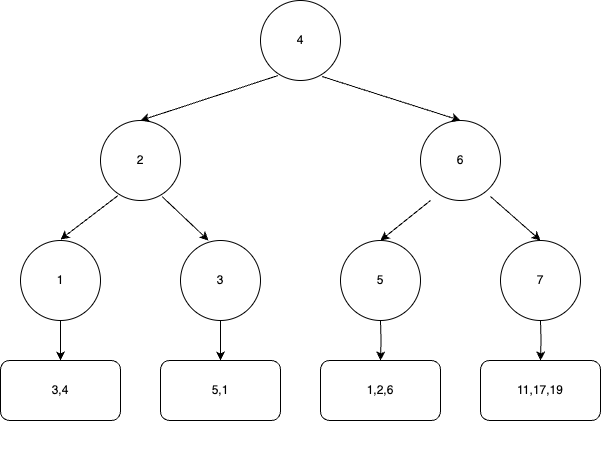
Come puoi vedere, ogni nodo dell’albero punta all’ID di un paese specifico, mentre i dati di questo nodo memorizzano un array di ID delle città incluse in quel paese.
Quindi, quando si interroga:
SELECT * FROM cities WHERE country_id = 1;
MySQL utilizza questo algoritmo:
- Viene consultato l’indice country_id per trovare il nodo con chiave “1” .
- Dopo aver ricevuto un array di identificatori di città, passa all’indice city_id , determinando la posizione di archiviazione fisica dei dati per ciascuna città.
- Con l’aiuto di posizioni definite, MySQL carica rapidamente i dati richiesti dal disco.
Questo approccio ottimizza la velocità di accesso ai dati, rendendo le query del database veloci ed efficienti.
Indici compositi (multicolonna)
Molto probabilmente, hai già capito dal nome che si tratta di indici su più colonne contemporaneamente. Dimentichiamo la nostra tabella delle città e immaginiamo un altro esempio. Immaginiamo che tu sia il proprietario di un negozio online. E, logicamente, c’è un ordine in esso. Cioè, abbiamo bisogno di una tabella che memorizzi le informazioni sull’ordine:
CREATE TABLE orders ( order_id INT AUTO_INCREMENT PRIMARY KEY, customer_id INT NOT NULL, product_id INT NOT NULL, order_date DATE NOT NULL, total_price DECIMAL(10,2) NOT NULL, shipping_address TEXT NOT NULL, order_status TINYINT NOT NULL );
Vogliamo aggiungere un indice alle colonne customer_id e order_status. Possiamo farlo utilizzando la seguente query SQL:
ALTER TABLE orders ADD INDEX customer_status_idx (customer_id, order_status);
Come avrai intuito, MySQL non creerà due indici separati su ciascuna di queste colonne, ma ci sarà un indice a più colonne.
Questo può essere pensato come un albero binario:
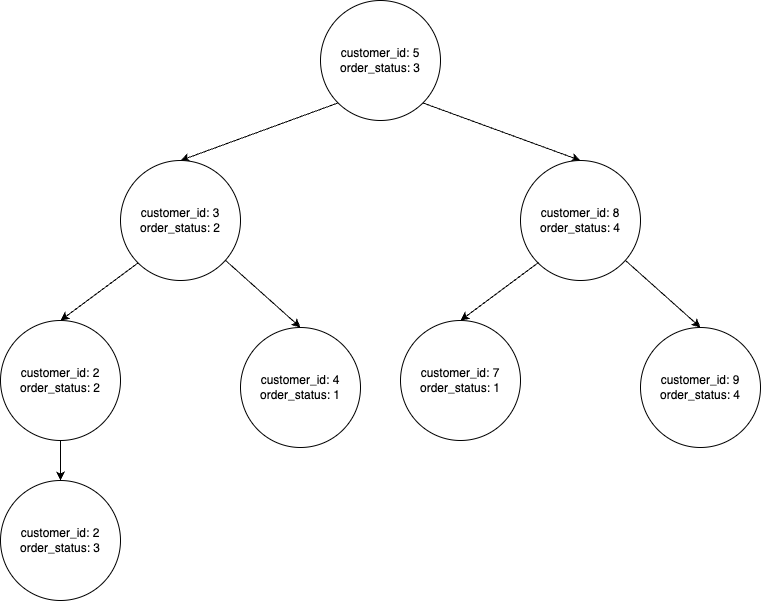
Ma prima di entrare nei dettagli, sottolineiamo un punto critico: l’ordine delle colonne quando si crea un indice complesso è di grande importanza. MySQL ha il concetto di selettività. E per dirla semplicemente, questa è l’unicità della colonna. Nell’indice a più colonne, la colonna più selettiva (cioè con valori più unici) deve essere la prima nell’indice.
Consideriamo la tabella degli ordini del tuo negozio online. Di norma, un utente effettua un numero limitato di ordini. E il numero medio di ordini con un determinato stato è molto superiore al numero medio di ordini per utente. Pertanto, è ottimale creare un indice (customer_id, order_status) .
Per determinare l’unicità di un campo in una tabella, è possibile utilizzare la seguente query SQL:
SELECT AVG(conteggio_valori) AS media_duplicati
FROM (
SELECT COUNT(*) AS conteggio_valori
FROM nome_tabella
GROUP BY nome_colonna
) AS sottoquery;
Questa query raggruppa i dati in base alla colonna specificata, contando il numero di righe per ciascuno dei suoi valori. Alla fine, otterremo il numero medio di righe per ciascun valore univoco in questa colonna, che ci aiuterà a stimare l’unicità del campo.
Indici di copertura
Spesso, quando parliamo di indici, li intendiamo come un modo per velocizzare la ricerca dei dati in una tabella. Ma gli indici non solo possono velocizzare la ricerca, ma anche ridurre la necessità di fare riferimento ai dati principali della tabella. Un indice di copertura è un indice che contiene tutte le informazioni necessarie per elaborare una query senza accedere ai dati effettivi nella tabella.
Torniamo alla tabella degli ordini dal negozio online. Nella pagina dell’utente, vogliamo visualizzare l’ordine tramite un determinato identificatore del cliente:
SELECT product_id, order_status FROM orders WHERE customer_id = 142;
Per ottimizzare questa richiesta, aggiungeremo un indice:
ALTER TABLE orders ADD INDEX cover_idx (customer_id, product_id, order_status);
Tutti i campi utilizzati nella query sono stati specificati al momento della creazione dell’indice. Ciò significa che quando si esegue questa richiesta in MySQL, non è necessario ottenere i valori product_id e order_status dal database, poiché tutte le informazioni sono già archiviate nell’indice.
Consideriamo alcuni casi più interessanti, entriando davvero nel cuore del funzionamento degli indici di copertura in MySQL.
Indice di copertura “parziale”
Consideriamo un caso leggermente diverso:
SELECT product_code FROM orders WHERE customer_id = 142;
Anche se l’indice contiene più colonne, in questo caso possiamo ancora sfruttarlo: basta che la query richieda solo alcune delle colonne presenti nell’indice. Questo è chiamato indice di copertura parziale. Se invece la query richiede una colonna non presente nell’indice, allora l’indice potrà essere utilizzato solo per filtrare customer_id; il valore di order_status dovrà essere recuperato dalla tabella principale, riducendo i vantaggi dell’indice di copertura.
Interazione con la chiave primaria
Consideriamo un’altra query:
SELECT order_id, product_id, order_status FROM orders WHERE customer_id = 142;
order_idè la chiave primaria, quindi MySQL la memorizza come indice clustered.- L’indice non clustered
cover_idxfunge da riferimento all’indice clustered. In questo caso, l’indice contiene tutte le informazioni necessarie: la query può essere eseguita in modo ottimale senza leggere ulteriormente la tabella.
Creazione di query in MySQL utilizzando gli indici
Quando si lavora con database di dimensioni medio-grandi, uno degli aspetti più critici è senza dubbio l’ottimizzazione delle query. Una query mal progettata può trasformarsi rapidamente in un collo di bottiglia, impattando negativamente sulle prestazioni dell’intera applicazione. In questo contesto, gli indici di MySQL rappresentano uno degli strumenti più potenti e allo stesso tempo più fraintesi.
In questo articolo analizzeremo in modo approfondito come funzionano gli indici in MySQL, come e quando vengono utilizzati dal Query Optimizer e quali sono i casi in cui una query può trarre beneficio da un indice o, al contrario, ignorarlo completamente. Non ci limiteremo a esempi teorici: vedremo codice SQL reale, casi pratici, test di performance e considerazioni concrete basate su scenari realistici.
L’obiettivo non è fornire una “ricetta magica”, ma aiutarti a sviluppare un ragionamento corretto nella progettazione degli indici e delle query.
Indice composito e ordine delle colonne
Iniziamo con un esempio molto semplice, che useremo come riferimento per spiegare il comportamento degli indici compositi (multi-colonna).
CREATE TABLE tabella_demo (
colonna_a INT,
colonna_b INT,
colonna_c INT,
colonna_d VARCHAR(120),
INDEX indice_abc (colonna_a, colonna_b, colonna_c)
);
La tabella tabella_demo possiede un solo indice, chiamato indice_abc, che copre le colonne colonna_a, colonna_b e colonna_c, in questo preciso ordine.
L’ordine delle colonne all’interno di un indice composito è fondamentale: MySQL utilizza il cosiddetto principio del prefisso sinistro. In altre parole, l’indice può essere sfruttato solo partendo dalla prima colonna e procedendo in ordine.
Query di ricerca con clausola WHERE
Esempi di query ben ottimizzate
Le seguenti query possono sfruttare pienamente o parzialmente l’indice indice_abc.
SELECT * FROM tabella_demo WHERE colonna_a = 10;
SELECT * FROM tabella_demo WHERE colonna_a = 10 AND colonna_b = 20;
SELECT * FROM tabella_demo WHERE colonna_a = 10 AND colonna_b = 20 AND colonna_c > 5;
SELECT * FROM tabella_demo WHERE colonna_a = 10 AND colonna_b IN (1, 2, 3, 4) AND colonna_c > 5;
SELECT * FROM tabella_demo WHERE colonna_a > 1;
Nell’ultimo esempio, MySQL potrebbe decidere di non utilizzare l’indice se il valore è molto piccolo e seleziona una grande porzione della tabella. In questi casi, una scansione completa potrebbe risultare più efficiente.
Esempi di query mal ottimizzate
Le query seguenti non sfruttano correttamente l’indice o lo utilizzano solo in modo parziale.
SELECT * FROM tabella_demo WHERE colonna_b = 10;
L’indice inizia da colonna_a, quindi non può essere utilizzato per filtrare solo su colonna_b.
SELECT * FROM tabella_demo WHERE colonna_a > 10 AND colonna_b = 5;
L’indice può essere utilizzato solo sulla prima colonna. Se l’intervallo su colonna_a è troppo ampio, l’ottimizzatore può decidere di ignorarlo.
SELECT * FROM tabella_demo WHERE colonna_a = 10 AND colonna_b >= 5 AND colonna_c = 3;
Una condizione di intervallo su colonna_b può impedire l’utilizzo dell’indice per colonna_c.
SELECT * FROM tabella_demo WHERE colonna_a = 10 AND colonna_c = 3;
L’indice può essere utilizzato solo per colonna_a. colonna_c viene ignorata perché colonna_b non è specificata.
Ordinamento e raggruppamento
Gli indici non servono solo per filtrare i dati, ma anche per evitare operazioni costose di ordinamento e raggruppamento.
Esempi di query efficienti
SELECT * FROM tabella_demo WHERE colonna_a >= 10 ORDER BY colonna_a LIMIT 20;
SELECT * FROM tabella_demo ORDER BY colonna_a DESC, colonna_b DESC LIMIT 10;
SELECT colonna_a, colonna_b, colonna_c FROM tabella_demo GROUP BY colonna_a, colonna_b, colonna_c LIMIT 50;
Esempi di query inefficienti
SELECT * FROM tabella_demo WHERE colonna_a = 10 ORDER BY colonna_b;
SELECT * FROM tabella_demo ORDER BY colonna_a ASC, colonna_b DESC;
SELECT * FROM tabella_demo GROUP BY colonna_b;
In tutti questi casi, l’indice non può essere utilizzato in modo ottimale a causa dell’ordine delle colonne o delle direzioni di ordinamento.
Indici su colonne testuali
Gli indici B-tree non sono limitati ai campi numerici. Possono essere utilizzati anche con campi testuali e temporali.
CREATE INDEX indice_testo ON tabella_demo (colonna_d);
Questo indice funziona per ricerche di prefisso:
SELECT * FROM tabella_demo WHERE colonna_d LIKE 'test%';
Ma non è utile per ricerche di suffisso:
SELECT * FROM tabella_demo WHERE colonna_d LIKE '%test';
Scelta dell’indice corretto
Consideriamo queste due query:
SELECT * FROM tabella_demo WHERE colonna_a = 10 AND colonna_b = 20;
SELECT * FROM tabella_demo WHERE colonna_a > 10 AND colonna_b = 20;
In questo caso, un indice su (colonna_b, colonna_a) potrebbe risultare più efficiente, perché la seconda query utilizza un intervallo sulla colonna colonna_a.
Gestione avanzata degli indici
Indici invisibili
ALTER TABLE nome_tabella ALTER INDEX nome_indice INVISIBLE;
ALTER TABLE nome_tabella ALTER INDEX nome_indice VISIBLE;
FORCE INDEX
SELECT * FROM nome_tabella FORCE INDEX (nome_indice) WHERE condizione;
USE INDEX
SELECT * FROM nome_tabella USE INDEX (indice_1, indice_2) WHERE condizione;
IGNORE INDEX
SELECT * FROM nome_tabella IGNORE INDEX (indice_1) WHERE condizione;
Questi suggerimenti devono essere usati con estrema cautela, perché possono peggiorare sensibilmente le prestazioni.
Svantaggi degli indici
Gli indici sono uno strumento molto interessante per velocizzare le query, ma ci sono anche alcuni punti negativi nel loro utilizzo. Occupano spazio su disco e rallentano le operazioni di inserimento, aggiornamento ed eliminazione dei dati. Maggiore è il numero di indici nel database, maggiore è lo spazio che occupano. Nel caso di tabelle di grandi dimensioni, potrebbe verificarsi un aumento significativo della quantità di spazio su disco utilizzato. Ciò è particolarmente importante da considerare quando le risorse di archiviazione sono limitate. Più indici sono presenti su una tabella, maggiore sarà il costo delle operazioni di scrittura, poichè anche gli indici corrispondenti devono essere aggiornati.
Pertanto, le operazioni sui dati che cambiano frequentemente possono diventare meno efficienti se sono presenti molti indici. Ciò è particolarmente rilevante per operazioni di modifica di dati di grandi dimensioni, in cui sono possibili ritardi significativi a causa degli aggiornamenti dell’indice.
Test di velocità su una tabella reale
Qui arriviamo alla parte più interessante di questo articolo: i test di velocità delle query quando la query utilizzava o meno l’indice. E verificheremo anche quanto gli indici rallentano le richieste di modifica dei dati.
Effettueremo test di velocità delle query sulla tabella recensioni_prodotti. Come avrai intuito, questa tabella memorizza le informazioni sulle recensioni degli utenti e le loro valutazioni sui prodotti di un negozio online.
CREATE TABLE recensioni_prodotti (
review_id INT AUTO_INCREMENT PRIMARY KEY,
product_id INT NOT NULL,
user_id INT NOT NULL,
valutazione INT NOT NULL,
testo_recensione TEXT,
data_recensione DATETIME NOT NULL,
FOREIGN KEY (product_id) REFERENCES prodotti(product_id),
FOREIGN KEY (user_id) REFERENCES utenti(user_id)
);
La tabella contiene 500.000 record di test. I tempi riportati sono in secondi.
Funzioni aggregate
| Query | Indice | Con indice | Senza indice | Miglioramento | Descrizione |
|---|---|---|---|---|---|
| AVG(valutazione) WHERE product_id = 205 | (product_id, valutazione) | 0,0025 | 0,5798 | 228x | Media valutazioni di un prodotto |
| COUNT(review_id) GROUP BY product_id | (product_id) | 0,5488 | 1,4423 | 2,6x | Prodotto con più recensioni |
Indici di copertura
| Query | Indice | Con indice | Senza indice | Miglioramento | Descrizione |
|---|---|---|---|---|---|
| SELECT user_id, valutazione WHERE product_id = 503 | (product_id, user_id, valutazione) | 0,0028 | 0,6242 | 219x | Elenco valutazioni per prodotto |
| ORDER BY data_recensione DESC | (product_id, data_recensione) | 0,0050 | 1,4109 | 278x | Recensioni ordinate per data |
Query di modifica dei dati
| Operazione | Senza indici extra | Con indici | Deterioramento |
|---|---|---|---|
| INSERT | 0,0146 | 0,0180 | 1,2x |
| UPDATE | 0,0234 | 0,0180 | Più veloce |
| DELETE | 0,0072 | 0,0179 | 2,5x |
I risultati mostrano chiaramente come un indice ben progettato possa migliorare le prestazioni anche di oltre 200 volte in alcuni casi, mentre le operazioni di scrittura subiscono un rallentamento contenuto.
Conclusioni
Gli indici non sono una soluzione universale, ma uno strumento potente se usato con consapevolezza. Devono essere progettati tenendo conto delle query reali, non aggiunti indiscriminatamente.
Oltre agli indici, esistono molte altre strategie di ottimizzazione: caching, riduzione dei dati restituiti, parallelizzazione delle query e, in alcuni casi, l’utilizzo di database differenti.
La chiave è sempre la stessa: capire il problema, misurare, testare e scegliere lo strumento giusto per il contesto giusto.

