L’indicizzazione del database è una tecnica che migliora la velocità e l’efficienza delle query del database. Crea una struttura dati separata che associa i valori di una o più colonne di una tabella alle posizioni corrispondenti sulla memoria fisica, consentendo al database di trovare rapidamente le righe per una query specifica senza dover scansionare l’intera tabella. Esistono diversi tipi di indici per cui è importante riflettere attentamente sulla strategia di indicizzazione del database e ottimizzarla.
Come i database creano indici
L’indicizzazione dei database viene in genere eseguita con un algoritmo che determina come creare e archiviare un indice. Il processo specifico per la creazione di un indice può variare a seconda del tipo di database in uso, ma in generale i passaggi generali sono i seguenti:
- Specifica la colonna o le colonne nella tabella del database da indicizzare: di solito sono quelle che vengono utilizzate più di frequente nelle query o nelle ricerche.
- Selezionare un algoritmo di indicizzazione appropriato per il tipo di dati da indicizzare: ad esempio, gli indici B-tree vengono generalmente utilizzati per indicizzare stringhe o dati numerici, mentre gli indici full-text vengono utilizzati per indicizzare dati di testo.
- Applicazione di un algoritmo di indicizzazione alle colonne selezionate, che crea una struttura dati che associa i valori nelle colonne alle posizioni delle voci della tabella corrispondente.
- Archiviazione dell’indice in una struttura di dati separata, di solito altrove su disco o in memoria, in modo che sia possibile accedervi in modo più efficiente rispetto ai dati della tabella corrispondente.
- Aggiornamento dell’indice in caso di aggiunta di nuovi record, eliminazione o modifica di record nella tabella.
La creazione di un indice può migliorare notevolmente le prestazioni delle query e delle ricerche nel database perché consente al sistema del database di trovare i record corrispondenti in modo più rapido ed efficiente. Tuttavia, l’indicizzazione può anche presentare degli svantaggi, come maggiori requisiti di archiviazione, inserimenti e aggiornamenti più lenti, pertanto è necessario valutare i pro e i contro prima di creare un indice.
Algoritmi di indicizzazione
Esistono molti algoritmi di indicizzazione utilizzati per ottimizzare la velocità delle operazioni di recupero dei dati creando indici di colonna della tabella. Ogni algoritmo di indicizzazione ha i suoi punti di forza e di debolezza. Ecco alcuni degli algoritmi di indicizzazione del database più popolari:
- B-tree
- Indice bitmap
- Indice hash
- GiST (Albero di ricerca generalizzato)
- Indice a testo integrale
B-tree
Un B-tree è una struttura di dati ad albero autobilanciato che viene spesso utilizzata come algoritmo di indicizzazione nei database. Ogni nodo dell’albero è costituito da un insieme di chiavi e puntatori a nodi figli; l’archiviazione dei dati avviene in una struttura gerarchica. Gli alberi B-node sono ordinati in modo da consentire di cercare, inserire ed eliminare rapidamente i dati.
Il più grande vantaggio dell’algoritmo B-tree è che riduce al minimo la quantità di I/O su disco richiesta per accedere ai dati, perché in un B-tree tutti i nodi foglia sono allo stesso livello e ogni nodo può memorizzare molte chiavi e puntatori . Il numero di chiavi e puntatori che possono essere memorizzati in un nodo è determinato da un parametro chiamato “ordine” dell’albero.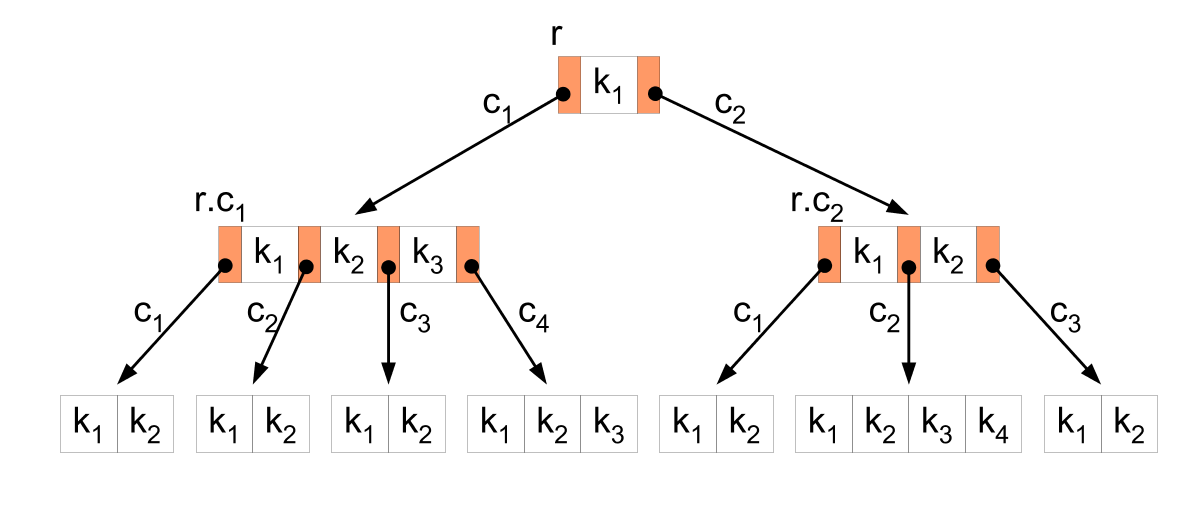 L’algoritmo B-tree funziona così:
L’algoritmo B-tree funziona così:
- Inizializzazione: quando viene creato un B-tree, viene creato un nodo radice vuoto. Un parametro che specifica il numero massimo di chiavi (“ordine”) che possono essere memorizzate in ciascun nodo controlla l’ordine dell’albero.
- Inserimento: quando un nuovo nodo viene aggiunto all’albero, l’algoritmo cerca innanzitutto un nodo foglia adatto in cui inserire la chiave. L’albero divide il nodo foglia popolato in due nuovi nodi e sposta la chiave mediana sul nodo padre. Finché non viene raggiunto il nodo radice, il processo di scissione può propagarsi attraverso l’albero. Grazie a questa procedura, l’albero rimane equilibrato e i nodi foglia sono alla stessa altezza.
- Cancellazione: quando una chiave viene rimossa dall’albero, l’algoritmo cerca il nodo che originariamente conteneva la chiave. Se il nodo foglia conteneva la chiave, la chiave viene recuperata e potrebbe essere necessario ribilanciare il nodo. L’algoritmo rimuove la foglia che precede o segue il nodo foglia, cancellando con essa la chiave se la chiave non viene trovata nel nodo foglia.
- Ricerca: nella ricerca di una chiave in un albero, l’algoritmo parte dal nodo radice e si sposta ricorsivamente sui rami finché non trova il nodo foglia desiderato. Il metodo di ricerca confronta la chiave che sta cercando con le chiavi contenute in ciascun nodo, quindi utilizza il puntatore corrispondente per navigare verso un nodo figlio che potrebbe contenere la chiave. Questo processo continua finché non viene trovata la chiave desiderata o finché non viene determinato che non si trova nell’albero.
Tuttavia, gli alberi B presentano alcuni svantaggi:
- Spreco di risorse: i B-tree consumano molto spazio, perché ogni nodo nell’albero contiene un puntatore ai nodi padre e figlio.
- Complessità: gli algoritmi utilizzati per inserire, eliminare e cercare i dati in un B-tree sono più complessi rispetto ad altre strutture di dati. Ciò complica l’implementazione e la relativa manutenzione.
- Aggiornamenti lenti: l’aggiornamento dei dati in un B-tree può essere relativamente lento rispetto ad altre strutture di dati. Ogni operazione di aggiornamento richiede molti accessi al disco e questo processo può essere lento per alberi B di grandi dimensioni.
Indice bitmap
L’indice bitmap è una tecnica di indicizzazione dei dati che utilizza una mappa di bit per indicare la presenza o l’assenza di un valore in una tabella che consente di migliorare le prestazioni delle query che implicano operazioni logiche complesse, come AND, OR e NOT. Le operazioni logiche vengono eseguite sui vettori di bit, che possono essere combinati in modo efficiente utilizzando operatori bit a bit. Questa è un’ottima tecnica di indicizzazione per tabelle a bassa cardinalità in cui il numero di valori univoci in una colonna è piuttosto piccolo rispetto al numero totale di righe, cioè in cui ogni valore viene visualizzato in un numero elevato di righe.
Le bitmap sono estremamente compatte e possono essere analizzate rapidamente per recuperare i dati. Gli indici bitmap sono molto utili per i data warehouse in cui è necessario scansionare rapidamente enormi quantità di dati. Sono anche utili per i database che hanno molte letture ma pochi aggiornamenti o inserimenti.
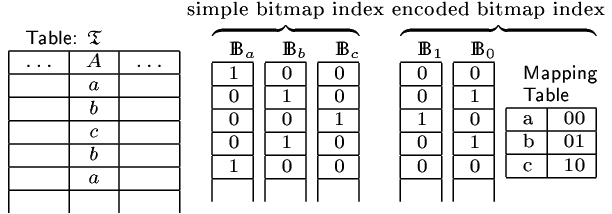
Come funziona?
- Viene creata una bitmap separata per ogni valore univoco della colonna. Ogni bitmap ha una lunghezza pari al numero di righe nella tabella.
- Se un valore è presente nella stringa, il bit corrispondente nella bitmap è impostato su 1 e, se è assente, è impostato su 0. (Immagina una tabella in cui la colonna “Sesso” ha due valori univoci, ad esempio “Maschio” e “Femmina”. Se questa colonna ha un indice bitmap, è possibile creare due bitmap, ciascuno di lunghezza uguale al numero di righe nella tabella. Quando in una riga compare un “Maschio” o una “Femmina”, il il bit corrispondente nella bitmap “Maschio” o “Femmina” è impostato su 1 e viceversa (se non è presente alcun valore “Maschio” o “Femmina”, il bit corrispondente è impostato su 0).
- Per eseguire una query utilizzando un indice bitmap, i valori bitmap corrispondenti nella query vengono combinati utilizzando gli operatori bit per bit AND, OR e NOT. Ad esempio, se vogliamo trovare tutte le righe in cui “Sesso” è uguale a “Maschio” e “Età” è maggiore di 30, dobbiamo prima ottenere la bitmap “Maschio” e la bitmap “Età > 30” dai rispettivi indici. Quindi combiniamo queste due bitmap utilizzando l’operatore AND bit per bit e otteniamo la bitmap finale con solo 1 in quelle posizioni in cui entrambe le condizioni sono vere. La bitmap finale viene quindi utilizzata per ottenere le righe dalla tabella che soddisfano la query.
Gli indici bitmap presentano molti svantaggi, tra cui:
- Grandi dimensioni: gli indici bitmap possono essere grandi, soprattutto quando si tratta di set di dati di grandi dimensioni. Di conseguenza, potrebbero essere meno efficienti di altre tecniche di indicizzazione.
- Colonne ad alta cardinalità: gli indici bitmap sono inefficienti per le colonne ad alta cardinalità dove il numero di valori univoci è molto elevato. In tali casi, gli indici bitmap possono diventare molto grandi e non entrare nella memoria.
- Distribuzione distorta dei dati: se i dati sono distorti, alcuni valori potrebbero avere una frequenza molto più elevata di altri e gli indici bitmap saranno inefficienti. Questo perché le bitmap per i valori più frequenti diventano molto grandi e possono dominare l’indice.
Indice hash
Un indice hash è una variazione di una tecnica di indicizzazione del database che utilizza una funzione hash per mappare le chiavi di indice alle posizioni dei record di dati corrispondenti. Si tratta di un metodo di indicizzazione veloce per query con corrispondenza esatta su una singola colonna.
La mappatura delle chiavi di indice alle posizioni dei record di dati corrispondenti consente ricerche e inserimenti veloci in un tempo O(1) costante. Tuttavia, questo metodo non funziona bene con query di intervallo o corrispondenze parziali e può soffrire di collisioni che possono essere gestite da varie tecniche di risoluzione delle collisioni.
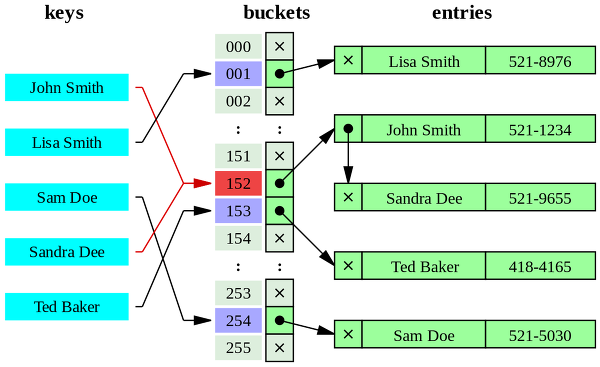
Come funziona?
Per spiegare come funziona un indice hash, diamo un’occhiata a un esempio. Supponiamo di avere una tabella di database contenente informazioni sui dipendenti, incluso l’ID utente. Vogliamo creare un indice hash nella colonna ID utente in modo da poter cercare rapidamente i dati utente in base al loro numero ID.
- Creeremo una funzione hash che prende un ID utente come input e genera un codice hash univoco come output. La funzione hash deve essere progettata per generare un set uniformemente distribuito di codici hash per distribuire uniformemente le voci tra i bin nel file di indice. In pratica, una funzione hash può utilizzare varie tecniche per generare un codice hash, come operazioni aritmetiche modulari o bit a bit.
- Creiamo un file di indice hash contenente un set di bucket, ciascuno corrispondente a un codice hash univoco generato dalla funzione hash. Ogni bucket contiene un puntatore a un file di database contenente voci per questo codice hash.
- Quando viene eseguita una query, una funzione hash viene applicata al valore della query per generare un codice hash. Il codice hash viene quindi utilizzato per trovare il bin corrispondente nel file indice hash. I record con lo stesso codice hash vengono archiviati nello stesso bucket, quindi possiamo semplicemente scansionare i record in quel bucket e trovare il record o i record corrispondenti. Se sono presenti collisioni (ovvero più voci con lo stesso codice hash), è possibile utilizzare tecniche come il concatenamento o l’indirizzamento aperto per risolverle.
- Per inserire una nuova voce nell’indice hash, applichiamo una funzione hash al valore della chiave della voce per generare il relativo codice hash, quindi inseriamo la voce nel bucket appropriato nel file dell’indice hash. Se non ci sono collisioni, l’inserimento può essere eseguito in un tempo O(1) costante, dato che dobbiamo solo calcolare il codice hash e inserire la voce nel bucket. Se ci sono collisioni, potremmo dover eseguire operazioni aggiuntive, come inserire una voce in un elenco collegato in un bucket o controllare altri bucket, fino a quando non viene trovato uno slot libero.
Gli indici hash presentano anche molti svantaggi, tra cui:
- Capacità di ricerca limitate: gli indici hash sono progettati per gestire solo ricerche di uguaglianza (ad esempio “trova tutti i record in cui la colonna A è uguale a un valore”). Non sono adatti per query di intervallo o di ordinamento.
- Collisioni: gli indici hash possono avere collisioni in cui più chiavi corrispondono allo stesso valore hash. Ciò può comportare un degrado delle prestazioni in quanto il database deve eseguire operazioni aggiuntive per risolvere i conflitti.
- Requisiti di dimensione di archiviazione imprevedibili: la dimensione di un indice hash è imprevedibile perché dipende dal numero di valori univoci nella colonna indicizzata. Ciò rende difficile pianificare i requisiti di archiviazione.
GiST
GiST (Generalized Search Tree) è una tecnica di indicizzazione del database che può essere utilizzata per indicizzare tipi di dati complessi come geometrie, testo o array. È una struttura ad albero bilanciata composta da nodi con più figli. Ogni nodo descrive un intervallo o un insieme di valori ed è associato a una funzione predittiva che verifica se il valore appartiene all’intervallo o all’insieme. La funzione predittiva dipende dal tipo di dati indicizzati e può essere adattata a diversi tipi di dati.
Come funziona?
Per illustrare come funziona un indice GiST, supponiamo di avere una tabella con dati spaziali contenente informazioni sulle città, inclusi i loro nomi e le coordinate in formato latitudine e longitudine.
- Definiamo un insieme di predicati e funzioni di trasformazione specifici per il tipo di dati spaziali indicizzati. In questo caso, dobbiamo definire un predicato che verifichi se il punto dato si trova nel riquadro di delimitazione descritto dal nodo nell’indice e una funzione di trasformazione che converte il punto in un insieme di chiavi in base alla sua posizione nel riquadro di delimitazione.
- Creiamo un file di indice GiST composto da molti nodi, ognuno dei quali descrive un riquadro di delimitazione che si estende su un intervallo di coordinate.Il nodo radice descrive l’intero intervallo di coordinate nella tabella del database e ogni nodo figlio descrive un sottoinsieme di questo intervallo. Ogni nodo è associato a una funzione predittiva e a una funzione di trasformazione specifica per il tipo di feature da indicizzare.
- Quando viene eseguita una query, il valore nella query viene convertito utilizzando la funzione di trasformazione in un set di chiavi.Le chiavi vengono quindi confrontate con i predicati associati a ciascun nodo dell’indice, a partire dal nodo radice. La ricerca continua lungo l’albero e seleziona il nodo figlio che contiene il valore dalla query. Il processo viene ripetuto finché non viene raggiunto un nodo foglia che contiene voci di indice che corrispondono al valore nella query.
- Per inserire una nuova città nell’indice, le coordinate della città vengono prima convertite in un set di chiavi utilizzando una funzione di trasformazione.Le chiavi vengono quindi inserite nei nodi indice corrispondenti, a partire dal nodo radice. Se il nodo è pieno, viene eseguita un’operazione di divisione per creare due nuovi nodi e le chiavi vengono distribuite tra i nodi.
GiST ha diversi inconvenienti da considerare:
- Velocità ridotta di inserimenti e aggiornamenti: le strutture con indice GiST possono essere più complesse delle strutture di indice tradizionali, il che può comportare inserimenti e aggiornamenti lenti.
- Più spazio su disco: le strutture di indicizzazione GiST possono richiedere più spazio su disco rispetto ad altre tecniche di indicizzazione perché memorizzano informazioni aggiuntive per supportare diversi tipi di ricerche.
- Non adatto a tutti i tipi di dati: GiST è ottimizzato per l’indicizzazione di tipi di dati complessi, come i dati spaziali, ma potrebbe non essere la scelta migliore per l’indicizzazione di tipi di dati più semplici, come numeri interi o stringhe.
- Aumento dei costi di manutenzione: a causa della complessità dell’implementazione, gli indici GiST richiedono più manutenzione rispetto agli indici tradizionali.
Indice Full-Text
L’indicizzazione full-text è una tecnica di indicizzazione utilizzata per migliorare le prestazioni di ricerca per le query di testo. A differenza degli indici tradizionali che memorizzano i valori delle singole colonne, un indice full-text memorizza il contenuto del testo di una o più colonne come insiemi di parole o token. Queste parole o token vengono utilizzati durante l’esecuzione di una query di ricerca per trovare rapidamente stringhe pertinenti.
L’indicizzazione full-text può migliorare significativamente le prestazioni delle query di ricerca di testo, soprattutto quando si lavora con grandi quantità di dati di testo. Tuttavia, richiede ulteriore spazio su disco e risorse di elaborazione, nonché un’attenta messa a punto delle opzioni di indicizzazione per prestazioni ottimali.
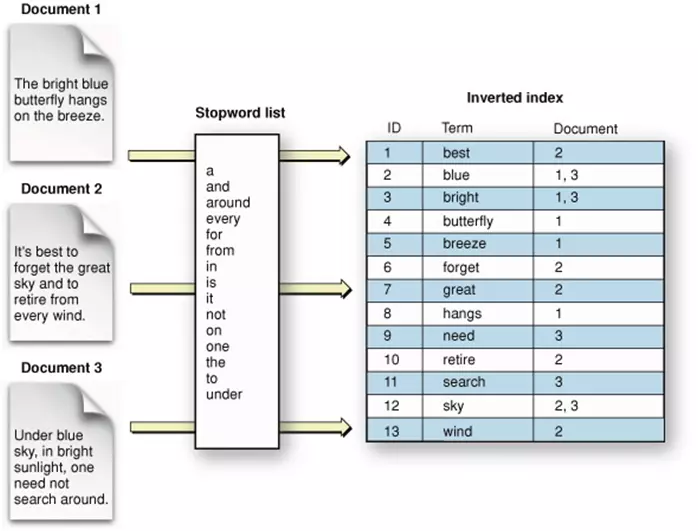
Come funziona?
Il processo di indicizzazione full-text consiste in diversi passaggi:
- Tokenizzazione: il contenuto di testo di una colonna indicizzata viene suddiviso in singole parole o token, che vengono quindi archiviati nell’indice. Quando si crea un indice full-text, il sistema di database prima analizza il contenuto testuale delle colonne indicizzate e poi lo suddivide in singole parole o token. Questo processo è chiamato tokenizzazione e può includere il filtraggio delle parole ignorate (ad esempio “il”, “e”, “o”) e lo stemming (riduzione delle parole alla loro forma base).
- Indicizzazione: i token vengono quindi indicizzati utilizzando una struttura dati speciale come un B-tree o un indice invertito. La struttura dell’indice consente una ricerca e un recupero efficienti delle righe contenenti i token specificati.
- Creazione ed esecuzione di query: il sistema di database utilizza un indice full-text per trovare righe contenenti token pertinenti. Il processo di ricerca confronta i token di query con i token indicizzati e recupera le righe che corrispondono alla query. I risultati della ricerca possono essere classificati in base alla loro rilevanza per la query, che viene calcolata utilizzando algoritmi come TF-IDF (term frequency-inverse document frequency).
L’indicizzazione full-text presenta alcuni svantaggi:
- Indicizzazione e velocità di ricerca ridotte: l’indicizzazione full-text può essere più complessa rispetto ad altre tecniche di indicizzazione, il che può comportare velocità di indicizzazione e ricerca lente, soprattutto in database di grandi dimensioni con molti campi di testo.
- Non adatto a tutti i tipi di dati: è più adatta per database contenenti grandi quantità di dati di testo. Potrebbe non essere la tecnica più efficiente per i database, almeno quelli contenenti informazioni numeriche o altre informazioni non testuali.
- Dipendenza dalla lingua:potrebbe non essere molto efficiente per i database multilingue in quanto richiede indici separati per ogni lingua e potrebbe non essere in grado di gestire le sfumature di lingue e scritture diverse.


