I Design Pattern sono delle soluzioni tipiche ai problemi che si verificano comunemente nella progettazione del software. Sono come “moduli” prefabbricati che possiamo personalizzare per risolvere un problema di progettazione ricorrente nel nostro codice. Tuttavia il modello non è un pezzo specifico di codice (per quello ci sono librerie e funzioni), ma un concetto generale per risolvere un problema particolare. I modelli sono spesso confusi con gli algoritmi, perché entrambi i concetti descrivono soluzioni tipiche ad alcuni problemi noti. Mentre un algoritmo definisce sempre un chiaro insieme di azioni che possono raggiungere un obiettivo, un modello è una descrizione di più alto livello di una soluzione. Il codice dello stesso pattern applicato a due diversi programmi può essere diverso.
La maggior parte dei pattern sono descritti in modo molto formale in modo che i programmatori possano riprodurli in molti contesti. Ecco le sezioni che di solito sono presenti in una descrizione del modello:
- L’intento del modello descrive brevemente sia il problema che la soluzione
- La motivazione spiega ulteriormente il problema e la soluzione che il modello rende possibile
- La struttura delle classi mostra ogni parte del modello e come sono correlate
- Il codice di esempio in uno dei più diffusi linguaggi di programmazione rende più facile cogliere l’idea alla base del modello
Chi ha inventato i pattern? Non c’è una risposta ben precisa a questa domanda. I Pattern sono soluzioni tipiche a problemi comuni nella progettazione orientata agli oggetti. Quando una soluzione viene ripetuta più e più volte in vari progetti, qualcuno alla fine le assegna un nome e la descrive in dettaglio. Fondamentalmente è così che viene scoperto uno schema.
Il concetto di pattern è stato descritto per la prima volta da Christopher Alexander in A Pattern Language: Towns, Buildings, Construction. Il libro descrive un “linguaggio” per progettare l’ambiente urbano. L’idea è poi stata ripresa daErich Gamma, John Vlissides, Ralph Johnson e Richard Helm che nel 1994 pubblicarono Design Patterns: Elements of Reusable Object-Oriented Software (il libro della banda dei quattro, a causa del suo titolo lungo), un manuale in cui viene applicato il concetto di design pattern alla programmazione. Il libro conteneva 23 modelli che risolvevano vari problemi di progettazione orientata agli oggetti ed è diventato un best-seller molto rapidamente.
Perché imparare i pattern?
In verità potremmo essere buoni programmatori anche senza conoscere un singolo pattern. Oppure potremmo già implementare dei pattern senza neanche saperlo. Ma allora perchè dovremmo conoscerli?
- I pattern sono un kit di strumenti di soluzioni collaudate a problemi comuni nella progettazione del software. Anche se non incontri mai questi problemi, conoscere i modelli è comunque utile perché ti insegna come risolvere tutti i tipi di problemi usando i principi del design orientato agli oggetti.
- I modelli di progettazione definiscono un linguaggio comune che può essere utilizzato da un team di sviluppo per comunicare in modo più efficiente. Puoi dire “Oh, usa un Singleton per quello” e tutti capiranno l’idea alla base del tuo suggerimento. Non c’è bisogno di spiegare cos’è un singleton se si conosce lo schema e il suo nome.
Classificazione dei pattern
I Pattern possono essere classificati in base al loro intento o scopo:
- Pattern di creazione forniscono meccanismi di creazione di oggetti che aumentano la flessibilità e il riutilizzo del codice esistente
- Pattern strutturali spiegano come assemblare oggetti e classi in strutture più grandi, mantenendo queste strutture flessibili ed efficienti
- Pattern comportamentali si occupano di una comunicazione efficace e dell’assegnazione di responsabilità tra gli oggetti
Vediamo di seguito un esempio per ogni categoria di pattern.
Abstract Factory
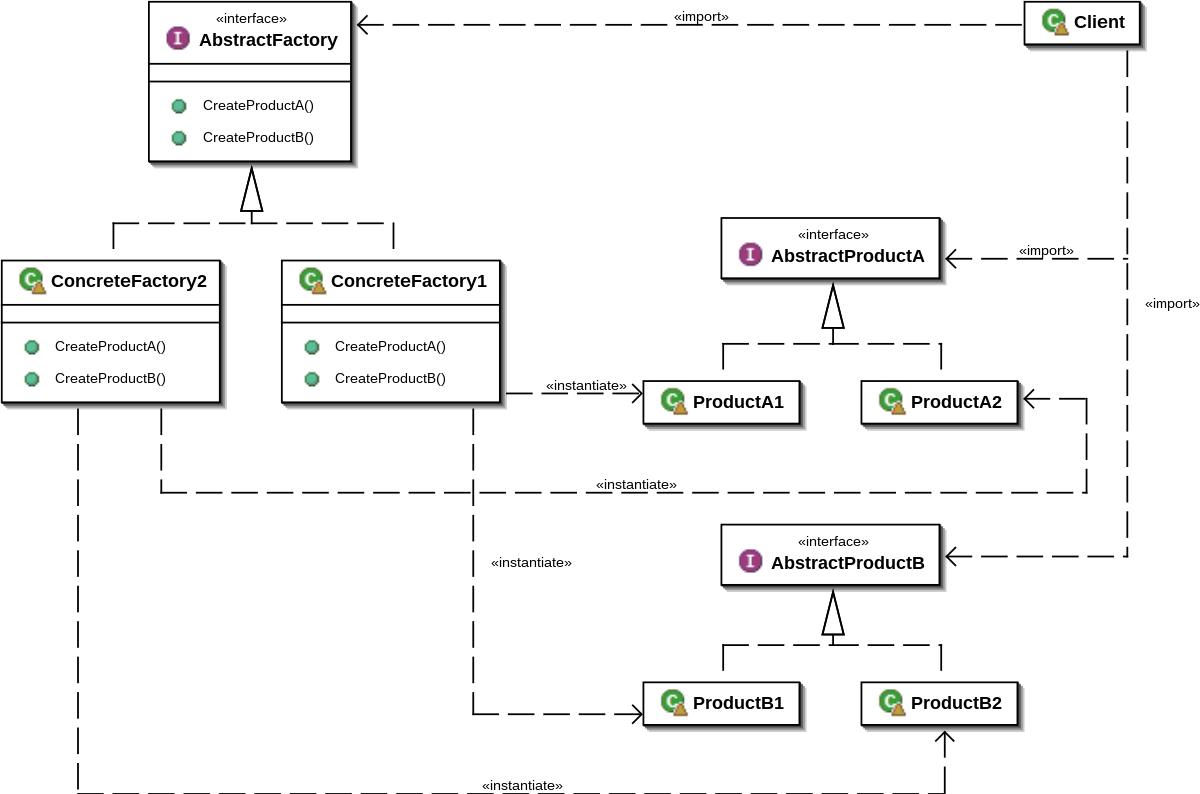
E’ un pattern di creazione che consente di produrre famiglie di oggetti correlati senza specificare la classe esatta dell’oggetto che verrà creato, facilitando la creazione di un sistema indipendente dall’implementazione degli oggetti concreti. L’utilizzatore conosce quindi solo l’interfaccia per creare le famiglie di prodotti ma non la sua implementazione concreta. I modelli Abstract Factory lavorano attorno al concetto di una super-fabbrica che crea altre fabbriche. Questa super-fabbrica è anche chiamata fabbrica delle fabbriche. Questo tipo di modello di progettazione rientra tra i modelli di creazione poiché questo modello fornisce uno dei modi migliori per creare un oggetto.
Immagina di creare un simulatore di negozio di mobili. Il tuo codice è composto da classi che rappresentano:
- Una famiglia di prodotti correlati, ad esempio: Sedia, Divano, Tavolino.
- Diverse varianti per ciascuna famiglia. Ad esempio, i prodotti sono disponibili in queste varianti: Modeno, Classico, Vittoriano…
Abbiamo bisogno di un modo per creare singoli oggetti di arredo in modo che corrispondano ad altri oggetti della stessa famiglia. Inoltre, non si desidera modificare il codice esistente quando si aggiungono nuovi prodotti o famiglie di prodotti al programma poichè i mobilifici aggiornano i loro cataloghi molto spesso e non dobbiamo cambiare il codice di base ogni volta che succede.
La prima cosa che suggerisce il modello Abstract Factory è dichiarare esplicitamente le interfacce per ogni prodotto distinto della famiglia di prodotti (cioè Sedia, Divano o Tavolino). Quindi possiamo fare in modo che tutte le varianti dei prodotti seguano tali interfacce. Ad esempio, tutte le varianti di sedia (es: SediaModerna, SediaClassica, SediaVittoriana) possono implementare l’interfaccia Sedia; tutte le varianti di tavolino possono implementare l’interfaccia Tavolino e così via.
La mossa successiva è dichiarare Abstract Factory , un’interfaccia con un elenco di metodi di creazione per tutti i prodotti che fanno parte della famiglia di prodotti (ad esempio creaSedia, creaDivano, creaTavolino). Questi metodi devono restituire tipi di prodotto astratti rappresentati dalle interfacce definite in precedenza: per l’appunto Sedia, Divano, Tavolino.
Poi, per ogni variante di una famiglia di prodotti, creiamo una classe fabbrica separata basata sull’interfaccia AbstractFactory. Una fabbrica è una classe che restituisce prodotti di un tipo particolare. Ad esempio, ModernFactory può solo creare oggetti di tipo SediaModerna, DivanoModerno, TavolinoModerno.
Il codice client deve funzionare sia con factory che con prodotti tramite le rispettive interfacce astratte. Ciò consente di modificare il tipo di fabbrica che si passa al codice cliente, nonché la variante di prodotto ricevuta dal codice cliente, senza violare il codice cliente vero e proprio.
Supponiamo che il cliente voglia una fabbrica per produrre una sedia. Il cliente non deve essere consapevole della classe della fabbrica, né importa che tipo di sedia ottiene. Che si tratti di un modello moderno o di una sedia in stile vittoriano, il cliente deve trattare tutte le sedie allo stesso modo, utilizzando l’interfaccia astratta Sedia. Con questo approccio, l’unica cosa che il cliente sa della sedia è che in qualche modo implementa il metodo siedi(). Inoltre, qualunque variante della sedia venga restituita, si abbinerà sempre al tipo di divano o tavolino prodotto dallo stesso oggetto di fabbrica.
C’è un’altra cosa da chiarire: se il client è esposto solo alle interfacce astratte, cosa crea gli effettivi oggetti factory? Di solito, l’applicazione crea un oggetto factory concreto nella fase di inizializzazione. Poco prima, l’app deve selezionare il tipo di fabbrica a seconda della configurazione o delle impostazioni dell’ambiente.
Adapter
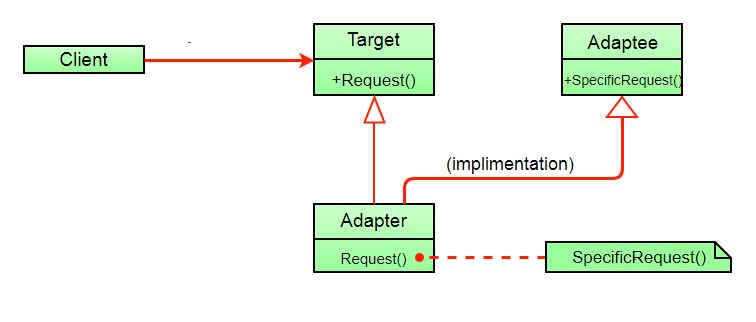
Adapter è un pattern strutturale che consente la collaborazione tra oggetti con interfacce incompatibili.
Immaginiamo di creare un’app per il monitoraggio del mercato azionario. Questo software scarica i dati azionari da più fonti in formato XML e quindi visualizza grafici e diagrammi comprensibili per l’utente. Ad un certo punto, decidiamo di migliorare la nostra app integrando una libreria di analisi AI di terze parti. Ma c’è un problema: la libreria di analisi funziona solo con dati in formato JSON.
Nel caso di librerie open source, possiamo modificare la libreria in modo che funzioni con XML. Tuttavia, ciò potrebbe causare problemi e interruzioni impreviste. Ma se nel caso peggiore, la libreria non fosse open source?
Possiamo creare un adapter. Cioè un oggetto speciale che converte l’interfaccia di un oggetto in modo che un altro oggetto possa capirlo. Un adattatore esegue il wrapping di uno degli oggetti per nascondere la complessità della conversione che avviene dietro le quinte. L’oggetto avvolto non è nemmeno a conoscenza dell’adattatore. Ad esempio, puoi eseguire il wrapping di un oggetto che opera in metri e chilometri con un adattatore che converte tutti i dati in unità imperiali come piedi e miglia.
Gli adattatori non solo possono convertire i dati in vari formati, ma possono anche aiutare gli oggetti con interfacce diverse a collaborare. Ecco come funziona:
- L’adattatore ottiene un’interfaccia, compatibile con uno degli oggetti esistenti.
- Utilizzando questa interfaccia, l’oggetto esistente può tranquillamente chiamare i metodi dell’adattatore.
- Alla ricezione di una chiamata, l’adattatore passa la richiesta al secondo oggetto, ma in un formato e un ordine previsti dal secondo oggetto.
A volte è persino possibile creare un adattatore bidirezionale in grado di convertire le chiamate in entrambe le direzioni.
Per risolvere quindi il dilemma dei formati incompatibili, possiamo creare adattatori da XML a JSON per ogni classe della libreria di analisi con cui il nostro codice lavora direttamente. Quindi modifichiamo il codice per comunicare con la libreria solo tramite questi adattatori. Quando un adattatore riceve una chiamata, traduce i dati XML in entrata in una struttura JSON e passa la chiamata ai metodi appropriati di un oggetto di analisi avvolto.
Observer
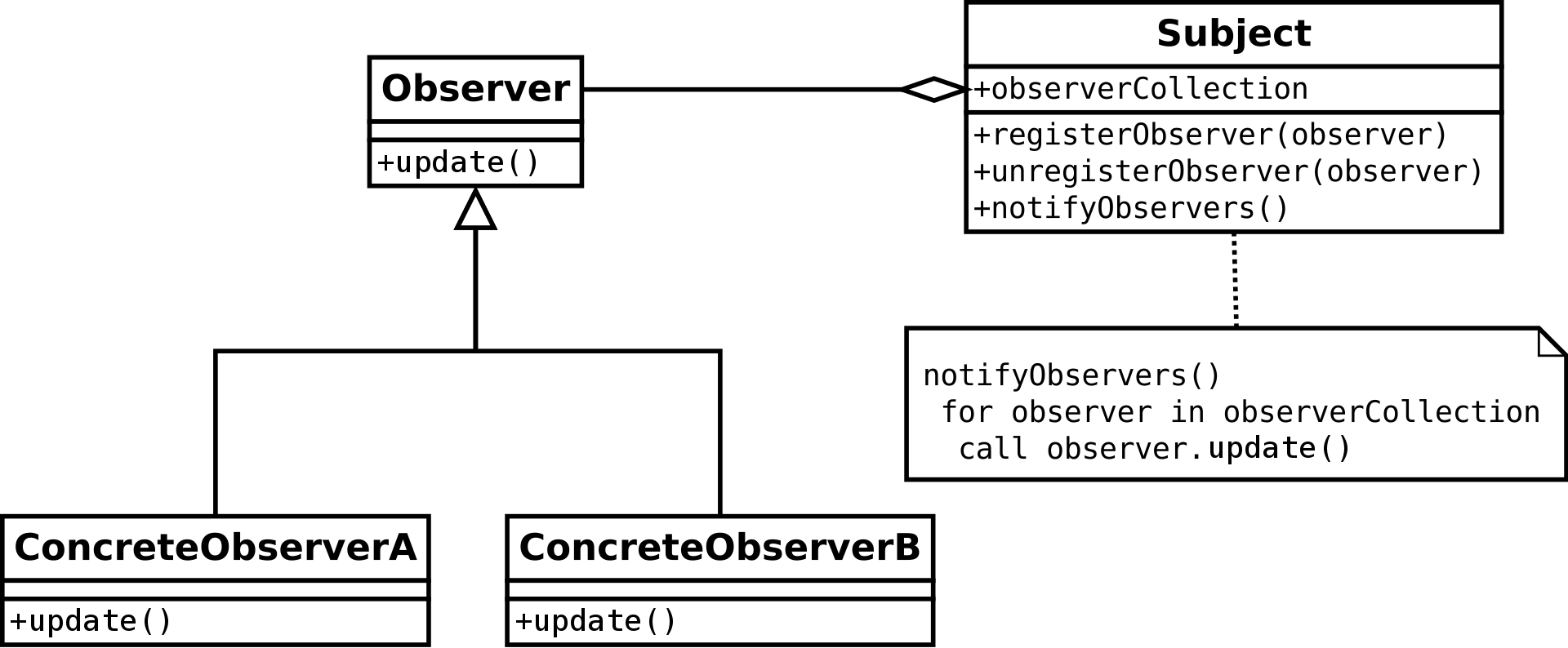
Observer è un pattern comportamentale che consente di definire un meccanismo di sottoscrizione per notificare a più oggetti gli eventi che si verificano all’oggetto che stanno osservando.
Immagina di avere due tipi di oggetti: Cliente e Negozio. Il cliente è molto interessato a un particolare prodotto (esempio il nuovo modello di iPhone) che dovrebbe essere disponibile nel negozio molto presto. Il cliente può visitare il negozio tutti i giorni e verificare la disponibilità dei prodotti. Ma mentre il prodotto è ancora in viaggio, la maggior parte di questi viaggi sarebbe inutile. D’altra parte, il negozio potrebbe inviare tonnellate di e-mail (che potrebbero essere considerate spam) a tutti i clienti ogni volta che diventa disponibile un nuovo prodotto. Ciò salverebbe alcuni clienti da viaggi infiniti al negozio. Allo stesso tempo, disturberebbe altri clienti che non sono interessati ai nuovi prodotti. Entriamo in una sorta di paradosso, poichè ci troviamo nella sicutazione in cui il cliente perde tempo a controllare la disponibilità del prodotto oppure il negozio spreca risorse avvisando i clienti sbagliati.
L’oggetto che notifica lo stato viene chiamato Publisher, mentre gli oggetti a cui verranno notificati gli stati vengono chiamati Subscriber. Il pattern Observer suggerisce di aggiungere un meccanismo di sottoscrizione alla classe publisher in modo che i singoli oggetti possano sottoscrivere o annullare la sottoscrizione a un flusso di eventi provenienti da quel publisher. In realtà, questo meccanismo è costituito da
- un campo array per memorizzare un elenco di riferimenti a oggetti abbonato
- diversi metodi pubblici che consentono di aggiungere e rimuovere abbonati da tale elenco
Ora, ogni volta che si verifica un evento importante per il Publisher, chiama il metodo di notifica specifico solo per i gli oggetti “abbonati”.
Le app reali potrebbero avere dozzine di diverse classi di abbonati interessate a tenere traccia degli eventi della stessa classe di publisher. E’ fondamentale che tutti gli abbonati implementino la stessa interfaccia e che l’editore comunichi con loro solo tramite quell’interfaccia. Questa interfaccia deve dichiarare il metodo di notifica insieme a una serie di parametri che l’editore può utilizzare per passare alcuni dati contestuali insieme alla notifica.
Una semplice analogia con il mondo reale è quella tipica dell’abbonamento ad una rivista (digitale o cartacea): l’editore invia i nuovi numeri direttamente alla nostra casella di posta subito dopo la pubblicazione o anche in anticipo. L’editore mantiene un elenco di abbonati e sa a quali riviste sono interessati. Gli abbonati possono lasciare l’elenco in qualsiasi momento quando desiderano impedire all’editore di inviare loro nuovi numeri di rivista. Se la nostra app ha diversi tipi di editori e desideriamo rendere gli abbonati compatibili con tutti loro, possiamo fare in modo che tutti gli editori seguano la stessa interfaccia. Questa interfaccia dovrebbe solo descrivere alcuni metodi di sottoscrizione. L’interfaccia consentirebbe poi agli abbonati di “osservare” gli stati degli editori senza accoppiarsi alle loro classi concrete.



. Alcuni esempi")