Un’implementazione della distanza di Levenshtein può essere fatta in qualsiasi linguaggio. In questo esempio, verrà utilizzato interamente il linguaggio MYSQL.
Per prima cosa, bisogna creare una routine su MySql. Aiutatevi con phpmyadmin per fare ciò. Eseguite direttamente il codice definito in questo listato per creare e aggiungere la funzione levenshtein() al vostro database MySql.
DELIMITER ;;
CREATE FUNCTION `levenshtein`( s1 VARCHAR(255), s2 VARCHAR(255) ) RETURNS int(11)
DETERMINISTIC
BEGIN
DECLARE s1_len, s2_len, i, j, c, c_temp, cost INT;
DECLARE s1_char CHAR;
DECLARE cv0, cv1 VARBINARY(256); -- max strlen=255
SET s1_len = CHAR_LENGTH(s1),
s2_len = CHAR_LENGTH(s2),
cv1 = 0x00,
j = 1,
i = 1,
c = 0;
IF s1 = s2 THEN
RETURN 0;
ELSEIF s1_len = 0 THEN
RETURN s2_len;
ELSEIF s2_len = 0 THEN
RETURN s1_len;
ELSE
WHILE j <= s2_len DO
SET cv1 = CONCAT(cv1, UNHEX(HEX(j))), j = j + 1;
END WHILE;
WHILE i <= s1_len DO
SET s1_char = SUBSTRING(s1, i, 1), c = i, cv0 = UNHEX(HEX(i)), j = 1;
WHILE j <= s2_len DO
SET c = c + 1;
IF s1_char = SUBSTRING(s2, j, 1) THEN
SET cost = 0; ELSE SET cost = 1;
END IF;
SET c_temp = CONV(HEX(SUBSTRING(cv1, j, 1)), 16, 10) + cost;
IF c > c_temp THEN
SET c = c_temp;
END IF;
SET c_temp = CONV(HEX(SUBSTRING(cv1, j+1, 1)), 16, 10) + 1;
IF c > c_temp THEN
SET c = c_temp;
END IF;
SET cv0 = CONCAT(cv0, UNHEX(HEX(c))), j = j + 1;
END WHILE;
SET cv1 = cv0, i = i + 1;
END WHILE;
END IF;
RETURN c;
END;
Se volete potete anche aggiungere quest’altra funzione, che restituisce la percentuale di esattezza della parola data.
CREATE FUNCTION `levenshtein_ratio`( s1 VARCHAR(255), s2 VARCHAR(255) ) RETURNS int(11)
DETERMINISTIC
BEGIN
DECLARE s1_len, s2_len, max_len INT;
SET s1_len = LENGTH(s1), s2_len = LENGTH(s2);
IF s1_len > s2_len THEN
SET max_len = s1_len;
ELSE
SET max_len = s2_len;
END IF;
RETURN ROUND((1 - LEVENSHTEIN(s1, s2) / max_len) * 100);
END
A questo punto l’unica cosa da fare è quella di creare una query per interrogare il database utilizzando in modo opportuno la funzione definita sopra.
SELECT CityName, levenshtein("romme", CityName) AS Lev
FROM tb_istat_cities
WHERE levenshtein("romme", CityName) BETWEEN 0 AND 2
ORDER BY Lev
Il risultato sarà questo:
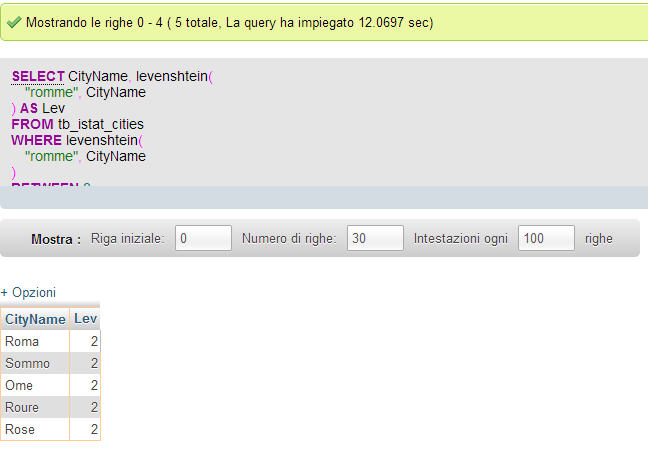
L’unico vero e grande problema è la lentezza dell’esecuzione dell’algoritmo. Per calcolare la distanza di levenshtein di “romme” su una base dati di 8,092 record, il tempo di esecuzione si aggira attorno ai 12 secondi, e peggiora in maniera esponenziale se la stringa da ricercare è più lunga (es. Castelbuono anzichè Roma). Purtroppo l’algoritmo contiene un doppio WHILE all’interno e questo potrebbe rappresentare un ostacolo, sopratutto in una tabella con migliaia di record.
Tuttavia possiamo cercare di ottimizzare la query MySql in fase di interrogazione in modo da cercare di dimezzare i tempi di ricerca. Una prima ottimizzazione è quella di selezionare solamente i termini più “vicini” a quello che stiamo cercando, confrontando la lunghezza degli stessi. Aggiungo quindi una condizione sulla lunghezza del campo CityName, che deve essere di un carattere più (+1) o meno (-1) lunga rispetto a ciò che sto cercando.
SELECT CityName, levenshtein("romme", CityName) AS Lev
FROM
(SELECT CityName FROM tb_istat_cities
WHERE LENGTH(CityName) BETWEEN LENGTH("romme")-1
AND LENGTH("romme")+1) AS MATCHES
WHERE levenshtein("romme", CityName) BETWEEN 0 AND 2
ORDER BY Lev
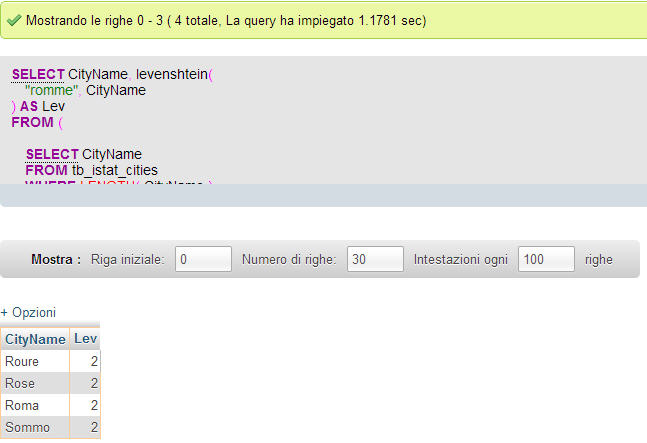
Abbiamo un netto miglioramento in termini di prestazioni in fase di esecuzione: 1,17 secondi contro 12 secondi del primo!
Esistono ovviamente altre ottimizzazioni, infatti ne ho implementata una che mi permette di raggiungere un tempo di esecuzione pari a 0,5740 secondi, ma in questo caso bisogna integrare qualche riga di codice PHP. Vi lancio la sfida di cercarne una! Qui sotto invece trovate un altra ipotesi di ottimizzazione…
[spoiler]
L’idea è quella di spezzare il nome in più parti e aggiungere un ulteriore condizione sul campo CityName in modo da filtrare e limitare i risultati velocizzando cosi l’esecuzione dell’algoritmo su un campione di dati molto più ristretto rispetto all’intera base dati.
SELECT CityName, levenshtein("costelbuona", CityName) AS Lev
FROM
(SELECT CityName FROM tb_istat_cities
WHERE LENGTH(CityName) BETWEEN LENGTH("costelbuona")-1
AND LENGTH("costelbuona")+1
AND (CityName LIKE '%cost%'
OR CityName LIKE '%oste%'
OR CityName LIKE '%stel%'
OR CityName LIKE '%telb%'
OR CityName LIKE '%elbu%'
OR CityName LIKE '%lbuo%'
OR CityName LIKE '%buon%'
OR CityName LIKE '%uona%'
OR CityName LIKE '%ona%'
OR CityName LIKE '%na%'
OR CityName LIKE '%a%')
) AS MATCHES
WHERE levenshtein("costelbuona", CityName) BETWEEN 0 AND 2
ORDER BY Lev
[/spoiler]
")
