Nell’epoca social in cui viviamo, tutti siamo dotati almeno di uno smartphone con singola, doppia, tripla o persino quadrupla fotocamera integrata. Quando scattiamo una foto, la prima domanda che ci viene in mente è se la foto scattata è venuta bene oppure no. Ma c’è una minoranza che invece, almeno una volta nella vita, si sarà chiesto com’è possibile che una fotocamera cosi piccola riesca a fare delle foto cosi belle. In questo articolo risponderemo proprio a questa domanda: come funzionano i sensori delle fotocamere digitali?
Un sensore, cosi come un qualsiasi altro dispositivo di acquisizione di immagini (scanner, telecamere, rilevatori di colore) utilizzano il modello RGB per codificare la luce acquisita in dati digitali. A differenza dei monitor, che proiettano luce, questi sensori la assorbono e la convertono in impulsi elettrici successivamente codificati ed elaborati.
In particolare ci concentreremo sul funzionamento dei due sensori più utilizzati e diffusi: CCD e CMOS.
Sensori CCD e CMOS
Entrambi inventati alla fine degli anni ’60 e ’70 (Savvas Chamberlain è stato un pioniere nello sviluppo di entrambe le tecnologie), CMOS e CCD sono le due tecnologie più importanti e comuni per il mercato dei sensori di immagine. Ognuno ha punti di forza e di debolezza in base al contesto e alle condizioni ambientali presenti al momento dello scatto.
I CCD (Charged-coupled device) sono sensori basati su una matrice di fotodiodi passivi in grado di accumulare una carica elettrica proporzionale all’intensità della radiazione elettromagnetica che li colpisce durante il tempo di esposizione della telecamera. La carica viene poi trasferita alla componente elettronica comune che legge le cariche elettriche accumulate dei diversi pixel e le traduce in tensioni.
Poiché il CCD è un dispositivo a pixel passivo (cioè senza elettronica a livello di fotodiodi) l’efficienza del sensore è molto alta e più sensibile: questo è un vantaggio nelle applicazioni dove la luce è piuttosto scarsa. Inoltre, poiché la componente elettronica è la stessa per tutti i pixel (o, almeno, per i pixel della stessa colonna), si può ottenere un’elevata uniformità di pixel. D’altra parte, il trasferimento della carica elettrica è piuttosto lento (tipicamente <20fps) e la tecnologia per i sensori CCD li rende molto costosi.
I CMOS (Complementary metal-oxide semiconductor) sono sensori basati su un array di pixel attivi: l’elettronica a livello di fotodiodo (tipicamente 3 o 4 transistor) traduce la carica elettrica accumulata nel fotodiodo in una tensione ben definita; in questo modo è sufficiente acquisire e campionare l’output di ogni pixel.
Poiché l’uscita dei pixel si basa sulla tensione (piuttosto che sulla carica), con i sensori CMOS è possibile ottenere frame rate più elevati grazie allo schema di lettura più semplice ed è possibile definire la regione di interesse (ROI) da acquisire. Questo schema di lettura ha lo svantaggio di sfruttare un rumore maggiore, dovuto ai transistor in ogni pixel e al cosiddetto rumore a schema fisso: una non omogeneità nell’immagine dovuta ai disallineamenti tra i diversi circuiti dei pixel (ne parleremo più avanti).
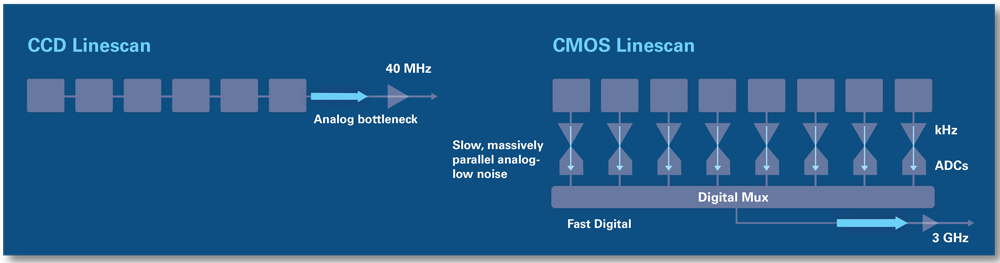
Il vantaggio prestazionale dei CMOS rispetto ai CCD merita una breve spiegazione. I sensori CMOS e CCD differiscono nel modo in cui la sorgente luminosa viene convertita in carica elettrica, trasformata in un segnale analogico e infine in un segnale digitale. I CCD hanno il problema di dover trasferire tutti i dati collezionati dai singoli pixel verso l’elettronica comune, che rappresenta già un primo collo di bottiglia. Inoltre, l’amplificatore ed il trasformatore devono lavorare su una grossa mole di dati e questo influisce sulla velocità.
Nei CMOS, essendoci un convertitore ed un amplificatore per pixel, il front-end di questo percorso dati è massicciamente parallelo. Ciò consente a ciascun amplificatore di avere una larghezza di banda ridotta.
La matrice Bayer
A prescindere dalla tecnologia, entrambi i sensori si basano su una tecnologia a matrice Bayer e funzionano secondo lo stesso principio: convertono la luce in carica elettrica e la elaborano in segnali elettronici: i colori vengono ottenuti filtrando la luce in ingresso, in modo da separare i tre primari RGB. I componenti sensibili ai diversi colori vengono raggruppati secondo una matrice a disposizione quadrata in cui vengono disposti gli elementi verdi, rossi e blu.

Lo schema rappresentato in figura, il cosiddetto filtro Bayer consiste quindi in un 50% di pixel verdi , 25% di pixel rossi e 25% di pixel blu. Come si può notare, i pixel verdi sono in numero doppio rispetto ai rossi e ai blu perché i nostri occhi sono più sensibili al colore verde, che quindi deve essere riprodotto con maggiore accuratezza.
Ad esempio in un pixel verde solo i raggi in ingresso la cui lunghezza d’onda è prossima a 550 nm (cioè luce verde) possono passare attraverso lo strato filtrante e possono essere assorbiti dal sensore (lo strato in grigio), mentre i raggi con altra lunghezza d’onda vengono respinti.
Una volta che la carica elettrica è stata raccolta, il secondo passo è ricostruire le informazioni di colore per tutti i pixel: questa onerosa operazione è chiamata demosaicing (o debayering).

Ad esempio, il pixel P(3,2) ha solo le informazioni sul blu, poiché il suo filtro di colore è blu. Per ottenere anche le coordinate rossa e verde una possibile scelta è quella di calcolare i due valori mediando il pixel rosso e verde più vicino.
In questo caso il valore del rosso sarà pari a:


Con una grande maschera utilizzata per la media, si può ottenere un colore più accurato, ma, d’altro canto, l’algoritmo sarà più pesante e, di conseguenza, il tempo di elaborazione sarà più lungo.
Global e Rolling Shutter (CMOS)
Global e Rolling shutter sono i due modi in cui un’immagine viene catturata e letta. Nelle fotocamere digitali con otturatore, il tempo di esposizione è lo stesso per tutti i pixel dei sensori (vedi figura: la lunghezza delle barre azzurre è la stessa per tutte le righe della matrice), ma c’è un ritardo tra le esposizioni di una riga e la successiva. In altre parole, questa architettura è “sequenziale”: la lettura avviene immediatamente dopo il tempo di esposizione della riga.

Questo schema fornisce un’immagine che non viene catturata tutta contemporaneamente, ma piuttosto spostata leggermente nel tempo: questo può essere un problema quando si cerca di fotografare ad esempio oggetti veloci che richiedono un frame rate elevato (le pale di un aeroplano).

Al contrario, il tempo di esposizione dei sensori di global shutter inizia e termina contemporaneamente (vedi figura: in questo caso le barre sono tutte allineate). In questo modo le informazioni fornite da ciascun pixel si riferiscono allo stesso intervallo di tempo in cui l’immagine viene acquisita. Qui, solo la lettura è sequenziale, ma la tensione campionata si riferisce ad un preciso istante di tempo per tutto l’array. Questo tipo di sensore è obbligatorio per le applicazioni ad alta velocità.




